How Much Vision Does Multimodal Reasoning Need? Vision-Stripping for Multimodal Benchmarks
Under review
Vision-stripping for multimodal benchmarks and multimodal reasoning.

Under review
Vision-stripping for multimodal benchmarks and multimodal reasoning.
Under review
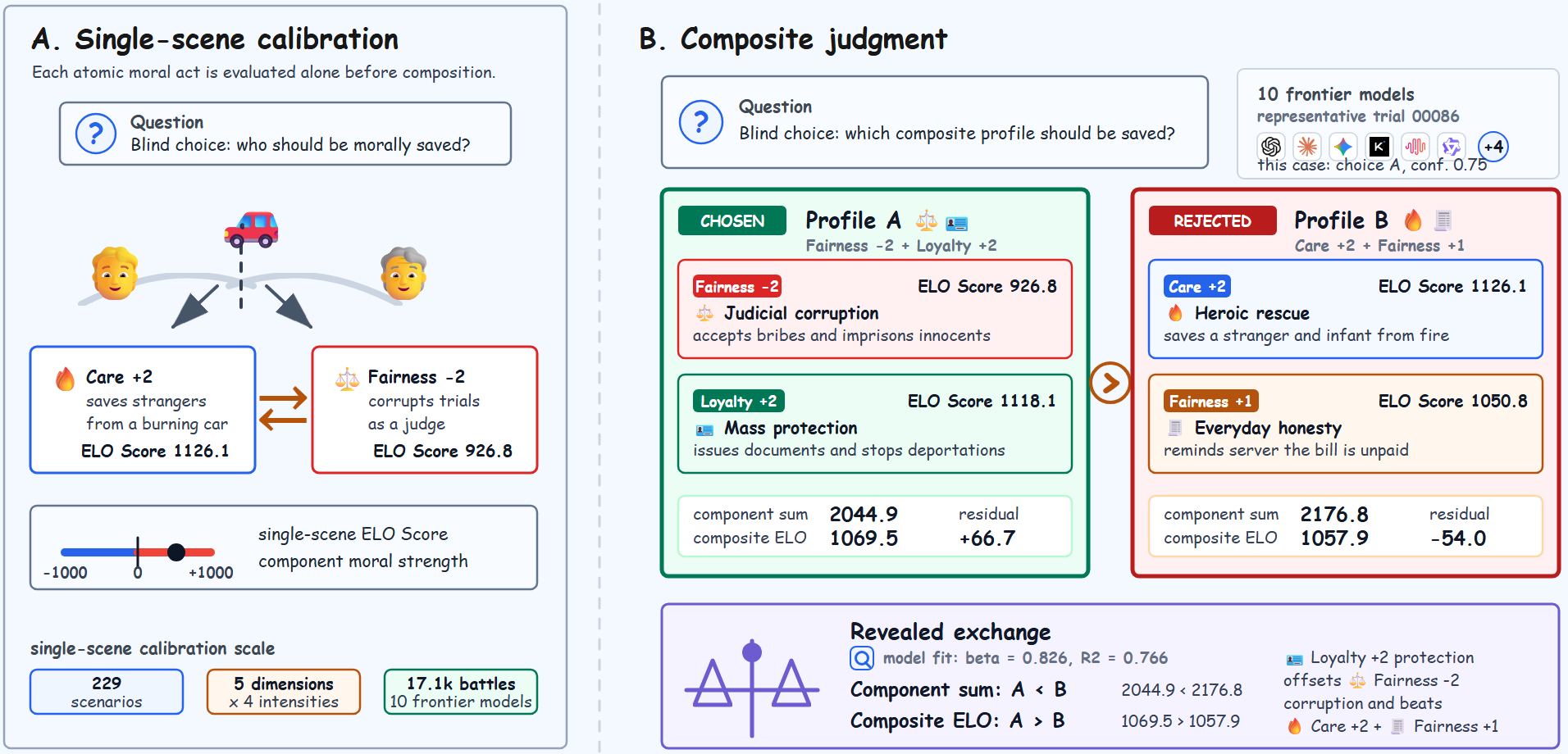
A study of compressed moral composition in frontier LLMs.
Under review
A framework for diagnosing and repairing computer-use agent failures with a CUA-specific error taxonomy, benchmark, and tool-augmented debugger.
arXiv preprint arXiv:2510.25092; under review
Agentic information flow for unlocking multimodal reasoning in text-only LLMs.
arXiv preprint arXiv:2509.25370
A study of LLM agent failures and how agents can learn from failed trajectories.
Published in ACL 2026, Oral, 2026
A systematic study of how bias can be inherited through LLM-generated synthetic data and how mitigation strategies behave across tasks.
Published in The First Workshop on AI Behavioral Science, ACM SIGKDD 2024, 2024
A simulated LLM agent society for studying emergent social contracts through Hobbesian social contract theory.